
Table of Contents
Author

Prachi Sharma
Solution Analyst, 4DAlert
In the world of data, things rarely stay perfect for long. Even the most carefully managed datasets can run into problems—errors sneak in, information gets outdated, and inconsistencies start to pile up. The result? Flawed insights that can send your decisions off track.
Most data quality issues go undetected in today’s complex pipelines. While some errors have minimal impact, others have led to serious consequences – costing lives, jobs, and significant money. With more companies building AI systems on top of their data, these risks are growing even larger.
It’s simply not possible to manually check for every potential data problem. That’s why smart monitoring systems that can learn what “normal” data looks like and automatically detect unusual patterns are becoming essential. These systems use unsupervised machine learning to spot issues across your entire data environment.
In this blog, we’ll debunk some of the most persistent myths about data quality and uncover the truths that data engineers, developers, and quality officers need to know. Keep reading!
Separating Facts from Myths in Data Quality
1. Truth: Data Quality Directly Impacts Business Metrics
• Misconception:Data quality is just a backend concern.
• Reality: Corrupt data flows through your pipelines into dashboards, ML models, and customer systems, affecting business metrics, prediction accuracy, and compliance requirements.
2. Truth: Automated Validation Requires Technical Depth
• Misconception: Simple rule checks catch most data issues.
• Reality: Effective validation needs statistical AI/ML pattern detection, schema enforcement, and relationship testing that scales with your data volume and complexity.
3. Truth: Real-Time Monitoring Is Critical Infrastructure
• Misconception: Scheduled quality checks provide sufficient coverage.
• Reality: Embedding validation directly in data pipelines with alerts on statistical anomalies helps catch issues before they reach production systems or analytical models.
4. Truth: Data Quality Requires Continuous Engineering
• Misconception: One-time data cleaning solves quality problems.
•Reality: Maintaining data integrity requires continuous monitoring with automated testing, version-controlled validation logic, and data observability that evolves with your architecture.
How Data Goes Wrong: Risks in the Processing Journey
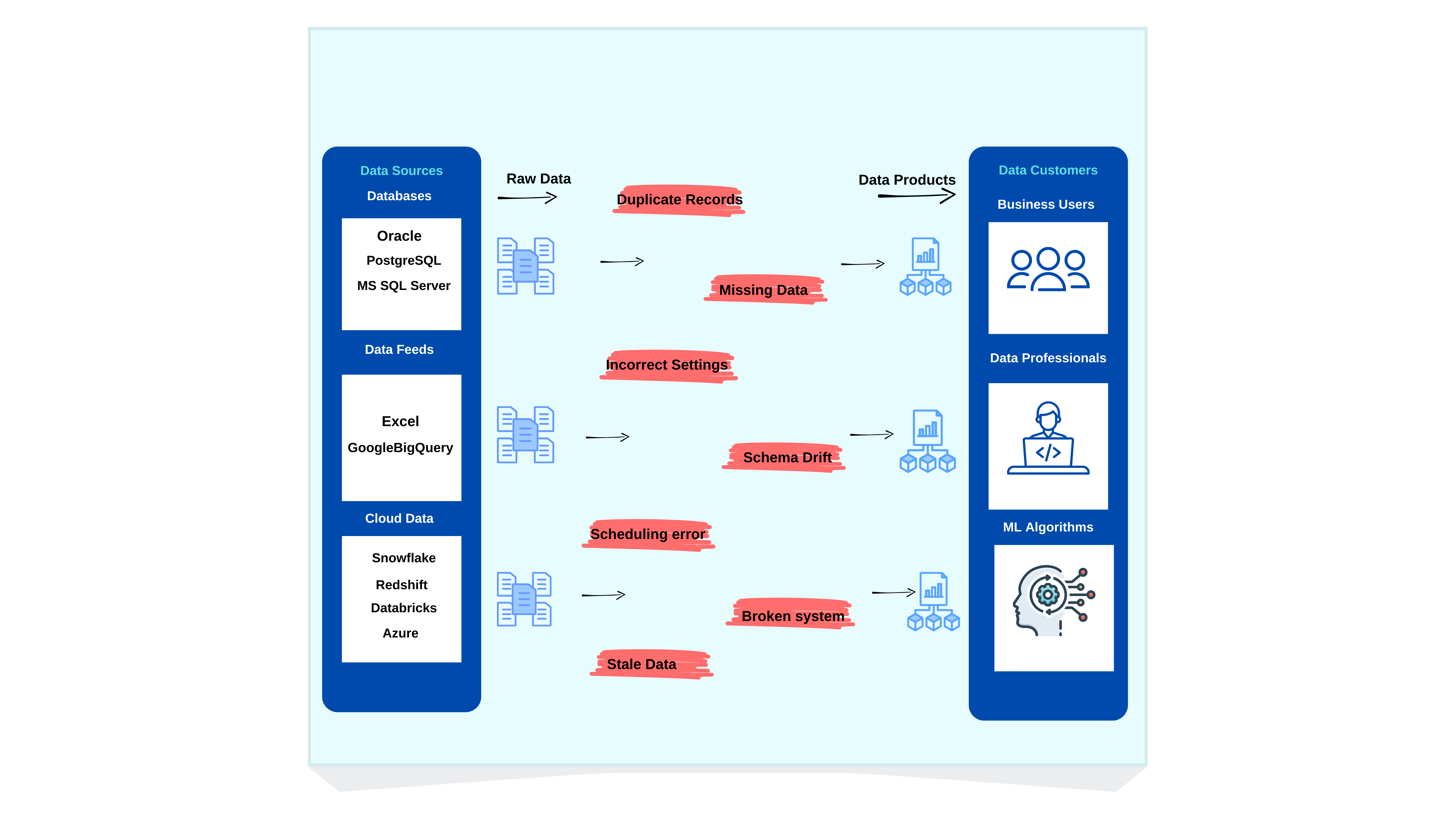
Every time data moves—whether it’s transported, copied, or transformed—the goal is to enhance its value. But at every step, there’s a risk that something will go wrong.
-
Bad Inputs:
Errors can start at the source. A faulty sensor, a typo in a manual entry, or inconsistencies in an upstream system can introduce flawed data that spreads downstream.
-
Mispackaged Data:
Metadata mistakes, missing headers, or unexpected API changes can cause systems to misinterpret data. Even accurate data can become useless if it’s not labeled correctly.
-
System Failures:
Software bugs, downtime, or broken data pipelines can result in lost, delayed, or corrupted data. A single processing failure can impact entire workflows.
-
Timing Issues:
If processes run out of sequence or at the wrong time, data can be duplicated, lost, or miscalculated—leading to reporting and operational errors.
-
Transformation Errors:
Poorly written scripts, incorrect aggregations, or flawed joins can distort data, making it unreliable for analytics and decision-making.
-
Configuration Mistakes:
Even properly maintained systems can fail if set up incorrectly—whether it’s a mismatched schema, an invalid rule, or an access control issue blocking critical data.
Not All Data Quality Solutions Are Created Equal – What to Watch For
When architecting robust data pipelines, the quality assurance layer is often underestimated. Some solutions offer shallow validation that breaks at scale, while others introduce so much overhead they become bottlenecks. Because in the end, there’s only better data, and the right solution should help you continuously improve data reliability without adding complexity. Here’s what you need to watch for when evaluating a data quality solution:
1. Can It Benchmark Your Current State?
You can’t improve what you don’t measure.” Before embarking on any data quality journey, you need to understand where you stand today.
A solution worth investing in should:
✅ Establish clear baselines across different business functions (Sales, Finance, HR).
✅ Quantify data quality across multiple dimensions (completeness, accuracy, consistency).
✅ Provide intuitive dashboards that translate technical metrics into business context.
✅ Provide intuitive dashboards that translate technical metrics into business context.
How 4DAlert helps: 4DAlert comes with pre-built dashboards that automatically categorize quality metrics by business function and quality dimension. These dashboards give both executives and data teams immediate visibility into what matters, with customization options to align with your specific organizational needs.
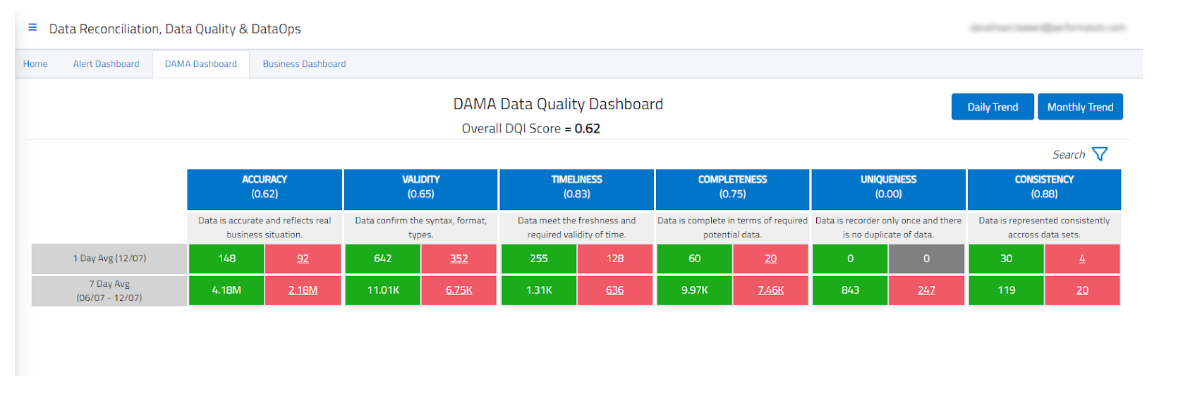
Without proper benchmarking, teams waste resources fixing problems that don’t impact the business while missing critical issues hiding beneath the surface.
2. Does It Track Quality Over Time?
Data environments change constantly with new sources, transformations, and business requirements. One-time quality assessments quickly become outdated as your data evolves.
Your data quality solution should:
✅ Measure metrics continuously across regular processing cycles.
✅ Visualize quality trends with clear, actionable dashboards.
✅ Track improvements against initial benchmarks with quantifiable results.
How 4DAlert helps: 4DAlert’s continuous data monitoring capabilities track quality metrics throughout your data journey, providing trend analysis that shows how your data quality is improving over time. This helps data teams demonstrate tangible progress to business stakeholders and justify continued investment in data infrastructure.
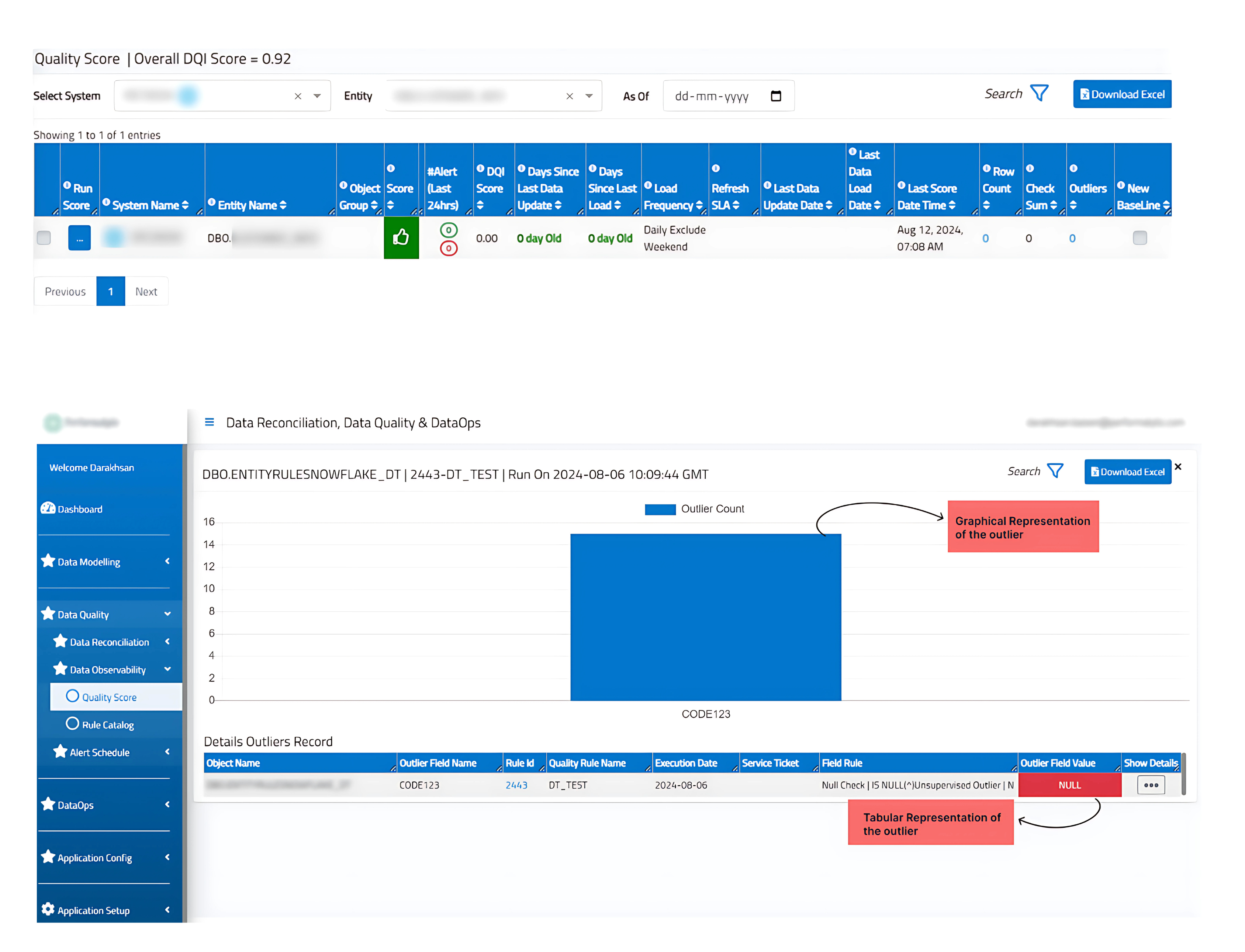
3. Will It Alert You Before Issues Impact Business?
Having 1% bad data might be acceptable for your analytics—but knowing when that becomes 2% is critical before it affects decisions. Outliers, anomalies, and unexpected shifts in data quality can quietly disrupt insights, making it essential to catch them early.
An effective alerting system should:
✅ Notify teams when quality metrics show worrying trends.
✅ Use intelligent thresholds that understand “normal” for your data patterns.
✅ Provide contextual information so teams can quickly identify root causes.
How 4DAlert helps: As its name suggests, 4DAlert excels at intelligent alerting. Its AI/ML algorithms analyze historical patterns to detect subtle shifts in data quality before they escalate into business problems.
The system uses smart thresholds that adapt to your data’s normal patterns, eliminating alert fatigue while ensuring you catch real issues.
4. Does It Go Beyond Basic Checks?
Traditional data quality focuses on simple validations:- Is this field empty??
– Does this email have the right format??
– Are there duplicate records??
While these are necessary, they’re insufficient for today’s complex data ecosystems. Modern data quality requires:
✅ Data reconciliation – Ensuring what’s in your analytics platform matches the source systems.
✅ Process validation – Verifying that ETL jobs didn’t just complete but completed correctly.
✅ Cross-system consistency – Confirming that the same customer or product looks the same across all systems.
How 4DAlert helps: 4DAlert goes beyond traditional data quality checks with automated data reconciliation capabilities. When ETL jobs show “green” but data is still wrong, 4DAlert can verify that the actual data—not just row counts—matches between source and target systems
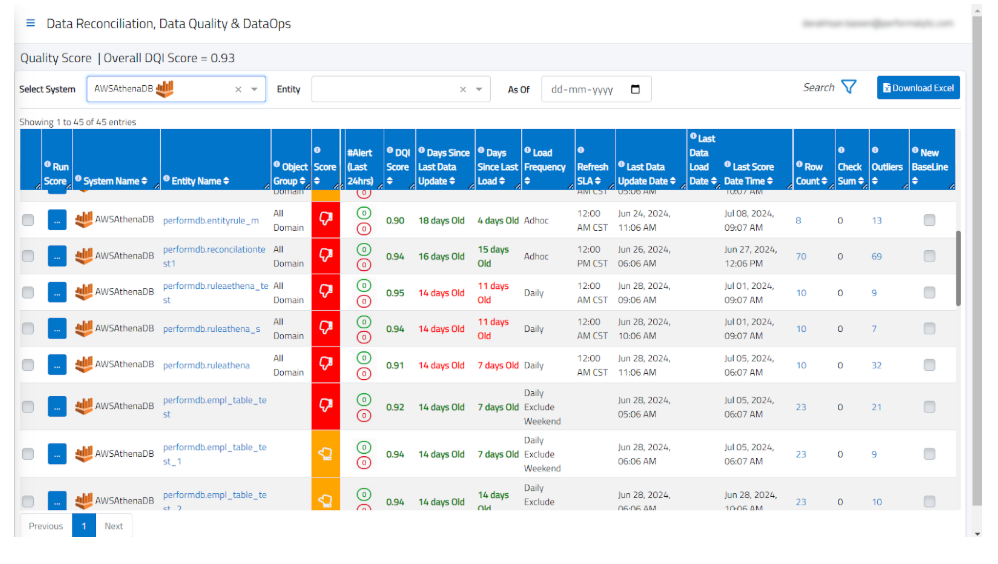
This advanced reconciliation can be scheduled to run after each data load, catching issues that traditional tools miss.
5. Does It Leverage AI/ML to Scale With Your Data?
As your data grows in volume and complexity, manually creating rules for every dataset becomes unsustainable.
Forward-looking solutions should:
✅ Automatically apply quality checks without requiring manual configuration.
✅ Use AI and machine learning to detect anomalies beyond predefined thresholds.
✅ Adapt to changing data patterns without constant rule updates.
How 4DAlert helps: 4DAlert sits on top of your data assets and applies automatic metrics such as freshness checks, volume monitoring, and pattern recognition without manual intervention. This AI/ML powered approach means you can cover 70% of quality checks automatically, only creating custom rules for organization-specific requirements
This automation frees your data team to focus on high-value analytics instead of spending time on routine validation tasks that could be handled by intelligent systems.
The Path to Data Excellence
Building trustworthy data systems requires systematic approaches, not ad-hoc fixes. The right data quality solution bridges technical implementation and business outcomes, serving both the data teams who manage information pipelines and the decision-makers who depend on reliable insights.
By addressing these five critical evaluation areas, organizations can transform data quality from a technical maintenance issue into a strategic business asset that delivers measurable value.
Book a personalized demo today to discover how our solution can help your organization build more reliable data systems with less effort.
Contact us at support@4dalert.com